
 |
| It's magic |
The main thing you need is a unit of work, which keeps track of all changes, writes them back to the database, and checks to make sure there are no conflicts when updating. You could, of course, have a 'dirty' flag for each object, and check each one at the end of your unit of work in order what to determine what to write back. But it's often more elegant to create a unit of work object and take care of objects that are new, dirty, or removed. The problem remains of determining the order of write backs.
If you have a lot of overlap between different units of work in a single session, you may want an identity map, which ensures that objects are only loaded once. This way, you can't accidentally modify two different instances of the same information in memory. An identity map could be located in a session object or as a static object in units of work.
Finally, since you may not want to load all objects into memory at the same time, you might consider implementing lazy loading. The idea is that you don't load data until you actually need it. This may defeat the purpose of O/R mapping, if it ends up leading to a lot of separate loads, but it is a natural extension of the identity map.
Now, much hinges on the actual map itself. How do your objects relate to each other and to the database? If your objects simply mirror your database schema, you could use an identity field which stores the primary key for each object / row. If you do this, you'll probably need a foreign key association between objects / tables.
Things become more complicated if you're making use of inheritance. You could have one table to manage an inheritance hierarchy. This is called single table inheritance. This may lead to lots of NULL values in the database table and difficulty in naming things in a single namespace. Another option is to use class table inheritance, in which you have one table for each class. This simplifies the relationship between objects and tables, but it leads to complex joins. You'll also have to be careful about foreign key relationships to other tables, as a primary key cannot be referred to by other tables. A variation on this pattern is what Fowler calls concrete table inheritance, in which you have one table for each level in an inheritance hierarchy. This should help with the foreign key relationships.
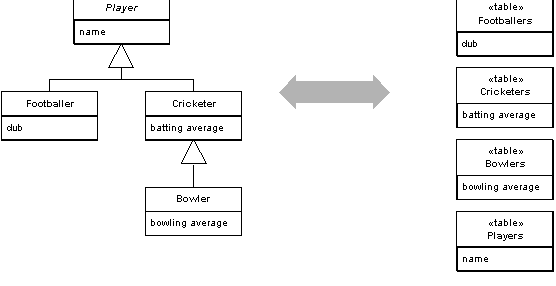 |
| An example of class table inheritance |
All this would be a lot to implement by hand, which is why Microsoft created the Entity Framework, first introduced in .NET 3.5. Java coders may try Querydsl. I haven't had a ton of experience dealing with OR behavioral issues, but I can understand the appeal of the EF. You can simply build your objects, build the relations, and then export a database from Visual Studio. I worry about the performance of these tools, but they seem flexible enough to allow for customization. Whether or not this customization is worth the development effort required is another question.

