From this deduction of our faculty of cognizing a priori there emerges a very strange result, namely that with this faculty we can never get beyond the boundaries of possible experience, that such cognition reaches appearances only, leaving the thing-in-itself as something actual for itself but uncognized by us. -- Imannuel Kant, The Critique of Pure Reason
The question of whether a computer can think is no more interesting than the question of whether a submarine can swim. -- Edsger Dijkstra, The Threats to Computing Science
In the late 1700's, Kant decided to demonstrate the limits of thought. This is not so easy, because we can think of all sorts of things that are impossible, like flying horses or projects that ship on time. Furthermore, the only tools we have are our pitiful human brains. The only way we can undertake to critique--i.e., set bounds to--pure reason is by reason itself. Kant's conclusion is that our understanding is limited by the structure of human experience. We can't be sure of grasping things as they truly are.
Which metaphysics is right is still up for debate, but we have made major inroads in the somewhat related field of computability. Of course, things are a bit easier here, since we're the ones who thought up the idea of computers, and they do what we tell them to do (for the most part). However, the idea is roughly parallel. Theoretical computer science is to computers what metaphysics is to thinking. Kant's question was: What is it possible to know? The question facing theoretical computer science is: What is it possible to compute? Since computers cannot think, as Dijkstra reminds us, we should be content with this more reasonable question.
In a later post, I'll talk about computation from the side of computability, which involves lots of serious proofs to determine what is logically possible for machines to do. Here, I'll discuss complexity theory, which asks: What is within the computational ability of actual computers, considering the real limitations of time and space?
One of the basic problems of computing is figuring out how much time it takes for a computer to solve a problem. As Donald Knuth found, it all depends on your problem and the algorithms you have available to solve it. Some problems take a polynomial (P) amount of time to be solved, which means that, as the input size increases, the amount of operations needed to solve the problem increases on the order of x
n, where n is an integer. If you have a list of 100 items, and your algorithm is on the order of x
2, it will take around 10,000 operations.
Some algorithms, however, grow with non-polynomial (NP) or exponential time as input size increases. They're on the order of n
x, where n is an integer. With small input sizes, this is not so bad. But with an input size of only 100 on an O(2
x) problem, you're looking at around 1,267,650,600,228,229,401,496,703,205,376 or > 1.3 * 10
30 operations. That is a lot. If you can do 10 trillion operations per second, that will still take far longer than the lifetime of the universe to finish--about 100 quintillion years.
NP problems are not esoteric. They're often graph problems, liking trying to determine the shortest distance someone can travel in order to visit a bunch of places without visiting the same one twice (the travelling salesman problem). Any problem involving scheduling or fitting items into boxes is NP too. I've often wondered how the modern world of logistics is possible, considering all of its problems are NP!
Theoretical computer scientists have shown that some problems are NP-complete, meaning that other NP problems can be reduced to them. They're the hardest possible problems to solve in NP time. The first problem shown to be NP-complete is Boolean satisfiability (or SAT), which involves determining the values of variables in a Boolean expression such that it evaluates to true. Since NP problems are so important and so intractable, many people have hoped to find a way to solve an NP-complete problem in polynomial time. If this happened, all NP problems would suddenly become tractable.
I'm not holding my breath for anyone to show that P=NP or to invent a non-deterministic computer, which would branch its computation at every decision and run NP problems in P time. So, what can you do?
Years of research have come up with a few ideas. If your run-time is NP, you can do a lot of preprocessing, as long as it takes polynomial time. You may be able to eliminate a lot of obviously wrong choices, or you may be able to figure out certain elements of a solution. For example, if your boolean satisfiability problem has a term by itself, it must be true. With preprocessing, you can get performance down to O(1.4
x) or so on some problems.
Another option is to find a slightly easier problem. If you don't care about obtaining the best possible solution, you can usually find an algorithm that performs no worse than twice as badly as the ideal. For example, greedy algorithms tend to do pretty well on graph problems, though there are pathological cases. For many applications, it's better to have a reasonably good answer than none at all.
To be honest, though, I've never run into a problem at work where I even had to consider NP solutions. Perhaps I have been lucky (or perhaps it's because I don't work in logistics!). It's worth wondering how important it is to know about the issues facing NP algorithms. For one thing O(1.1
x) is better than O(x
10). Furthermore, there are problems that are even harder than exponential problems, such as finding a winning move in chess. Each move has a tree of exponential solutions to investigate.
I think the important thing to understand is that certain problems get really hard to solve really fast. Computers follow instructions, and if the only possible instructions require looking at a huge number of possible solutions, it's going to take a long time. Humans process a lot of information very quickly because we filter out much more than we pay attention to. Until computers become better pattern-matchers, they won't be able to match our speed in processing large input sizes. This is why there is so much interest around machine learning now, though programming computers to be better pattern-matchers will have its own problems, since heuristics always fail for outliers (see Kahneman's
Thinking, Fast and Slow).
Most theoretical computer scientists do not think P=NP. This is probably a good thing--at least for the time being. Cryptography, for example, would cease to be possible if prime factorization algorithms could be solved in polynomial time. You remember
Sneakers, right? Anyway, I think it's more interesting to try to make computers smarter than to try to make them faster at doing stupid things. In other words, we shouldn't hope to get computers to grasp the thing-in-itself through further and further analysis; we should seek to change the structure of their 'experience.'

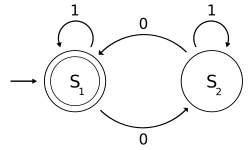 The first, and simplest, model of a computer is a state machine. A state machine has a finite set of states and inputs it can receive. It has a start state and at least one final state. Its next state depends on its current state and the input it receives. The language it accepts is the set of inputs that leads to a final state. For example, the machine to the right accepts the inputs ∅, 1, 00, 0101, and an infinite number of other inputs. All these inputs together define its language.
The first, and simplest, model of a computer is a state machine. A state machine has a finite set of states and inputs it can receive. It has a start state and at least one final state. Its next state depends on its current state and the input it receives. The language it accepts is the set of inputs that leads to a final state. For example, the machine to the right accepts the inputs ∅, 1, 00, 0101, and an infinite number of other inputs. All these inputs together define its language.






