
Martin Fowler and Pramod Sadalage provide some much-needed perspective in their new book SQL Distilled. They don't see Oracle or SQL Server going anywhere any time soon. There are three main reasons for this. First, SQL has forty years of production experience. Big banks are not going to jump to Hadoop for their transactional systems. Second, it's easy to find programmers with SQL experience. Not so for NoSQL. Third, and perhaps most importantly, NoSQL and SQL are meant to solve different problems.
Fowler and Sadalage suggest two main reasons for going NoSQL: programmer productivity and data access performance.
Column-oriented and document store NoSQL databases can be more productive for programmers because they can store objects as JSON. There is no need for ORM mapping, which has been called the 'Vietnam of computer science.' Of course, many problem domains require too many or too complex of relationships between objects to allow for this.
The main reason NoSQL databases were created was scaling. Companies like Amazon and Google pioneered NoSQL because they had way too much data to store in SQL databases. Frankly, I don't think very many companies need to worry about scaling to Google size, or they can cross that bridge when they get to it.
One of the things Fowler and Sadalage emphasize is that we don't yet have enough experience to even say when we should choose NoSQL over SQL. Still, they point to a storage architecture that takes advantage of the strengths of all systems. They call this polyglot persistence.
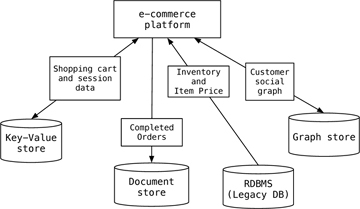
For example, in a eCommerce system, a shopping cart could be served by a key-value store like Riak; the orders and products could be an OLTP database like Oracle; order history could be in a document store like MongoDB; and customer suggestions could be maintained by a graph database like Neo4j. Of course, we could add to this a warehouse using Pentaho or a logging system using a column-family store like Cassandra.
The important thing is to gain familiarity with these products and to do POC's demonstrating the strengths and weaknesses of different approaches. For instance, I like the idea of a polyglot approach, but this puts a lot of pressure on the DBA's. In large organizations, you often have a split between developers, who know what needs to be done, and DBAs, who have the power to do it. Maintaining a number of data stores isn't for the faint of heart.
On that note, I'll be working on putting some MongoDB into practice with Python, Django, and a bunch of other things I don't know anything about. More to follow...
No comments:
Post a Comment