
If you're a database guy like me, you're probably wondering what you can do with a key-value store. Using key-value tables is a SQL anti-pattern. Even if you get performance and scalability (which I'll discuss in an upcoming post), it's hard to see how you could do any interesting queries with a key-value system.
One thing to note is that a file system is basically a key-value store. The key is the file name and the value is the contents of the file. You can do searches on file systems, but you can't really do much querying. If your data needs are more like a file system than complex analytics, a key-value store might be right for you.
I also finally learned what the MapReduce algorithmic framework does. You may have heard of MapReduce (amongst many other new technologies) in connection with Hadoop. MapReduce will probably go down in history as one of Google's greatest contributions to computer science (along with the PageRank algorithm).
MapReduce is inspired by a functional language, LISP. The idea is simple: take the algorithm to the data. In a highly distributed and scalable system, it's not feasible to move data to a processor in order to aggregate and slice it. You have to do any processing in-place. The way to do this is to map your keys to some kind of broader category and then run a reduce algorithm over the mapped data to pick out only the information you need.
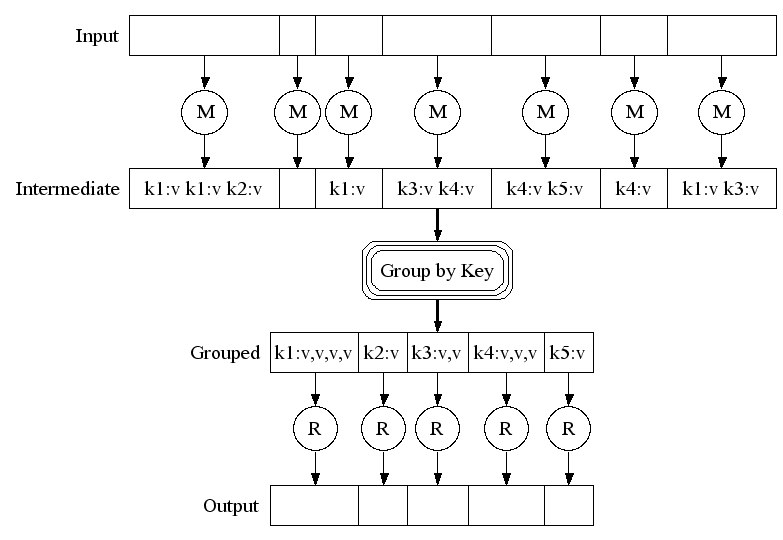
For example, let's say your key-value store contains documents, and you want to count the number of documents beginning with the letter 'X' that contain the word 'tibialoconcupiscent'. In this case, you would map all documents with a key like 'x*', such as 'xerophagy.pdf'. Your reduction algorithm would simply return 1 for every case of the word and 0 otherwise. This reduction could be run on each server, a group of servers, and then all servers, returning a single (probably small) number.
This framework may seem limited, and it is. Key-value systems just aren't great for complex querying. One reason SQL has been so popular is that it allows for unlimited combinations of queries. You're limited in the ways you store data, and you have to wait for the system to write the data to disk in order to ensure consistency, but you can read the data in lots of interesting ways. That's why it's called a Structured Query Language.
(Riak does let you do some more interesting things because you can create links between different keys that define any kind of relationship between them. These links are just metadata. You can MapReduce across links, but the basic idea is the same.)
Now, where would I use Riak? There are a good number of production users already. I would think it would be best used in systems that don't require a lot of complex querying or complex data types. For instance, it could store webpages, messages, or other content. Unless you have a huge amount of data or require very fast writes, it's probably not necessary. But if you're looking to grow fast, it might be the right choice.
No comments:
Post a Comment